Typescript Pick 'n' Mix
Originally posted on the Scott Logic blog
In this article, I discuss how the Pick utility type can help satisfy the Interface Segregation Principle in TypeScript
When an interface declares many unrelated methods, developers must implement functionality that's never used. This wastes time, makes code less readable, and can lead to runtime type errors after 'implementing' the interface with method stubs. The Interface Segregation principle (one of the 5 SOLID principles) warns against this.
It states:
No client should be forced to depend on methods it does not use
That's the theory, anyway. What does interface segregation look like in practice?
Defining the Problem
I will be using the same example throughout this post. It is a (fairly unrealistic) implementation of a list of strings. All code is available on GitHub.
Example
interface StringList {
/**
* @param elem The element to add
* @param idx 0-indexed, the index of the new element
*/
add(elem: string, idx: number);
/**
* @param idx 0-indexed, the index of the element to remove
*/
remove(idx: number): boolean;
/**
* Returns the index of an element, or <code>null</code> if it is not in the list
*/
indexOf(elem: string): number | null;
}
function contains(list: StringList, elem: string): boolean {
return list.indexOf(elem) !== null;
}
function setElement(list: StringList, idx: number, newElem: string): boolean {
const removed = list.remove(idx);
if (!removed) return false;
list.add(newElem, idx);
}
function replaceElement(
list: StringList,
oldElem: string,
newElem: string
): boolean {
const idx = list.indexOf(oldElem);
if (idx === null) return false;
return setElement(list, idx, newElem);
}
In theory, there should be nothing stopping us using the contains function on an immutable (read-only) list.
It only uses the indexOf function and wouldn't be affected by the missing add and remove methods.
In practice, the TypeScript compiler won't like that.
Given the immutable list implementation:
List
const listValues = ["hi", "there", "friend"];
const list = {
indexOf(elem: string): number | null {
const idx = listValues.indexOf(elem);
if (idx === -1) return null;
return idx;
},
};
We can't call contains(list, "friend") because list does not implement the add or remove methods on StringList.
In JavaScript, I could call contains without any problems because I know it only uses the indexOf method.
In contrast, the TypeScript compiler follows the method signature, which requires that list implements all of StringList - including add and remove.
One quick and hacky solution is to use a cast, calling contains(list as StringList, "friend").
This just disables the type checking, meaning we can't guarantee that contains doesn't call add or remove.
Why even use TypeScript at that point?
Another option is to implement the extra methods with stubs:
Stubs
const listValues = ["hi", "there", "friend"];
const list = {
add(elem: string, idx: number) {
throw new Error("not implemented");
},
remove(idx: number) {
throw new Error("not implemented");
},
indexOf(elem: string): number | null {
const idx = listValues.indexOf(elem);
if (idx === -1) return null;
return idx;
},
};
This is even worse, because now contains(list, "friend") works but the compiler also allows replaceElement(list, "hi", "hello").
Since replaceElement uses add and remove, this will cause a runtime error.
The only remaining option is to actually implement the functionality:
Functional
const listValues = ["hi", "there", "friend"];
const list = {
add(elem: string, idx: number) {
listValues.splice(idx, 1, elem);
},
remove(idx: number) {
const deleted = listValues.splice(idx, 1);
return deleted.length > 0;
},
indexOf(elem: string): number | null {
const idx = listValues.indexOf(elem);
if (idx === -1) return null;
return idx;
},
};
But we only wanted to call contains(list, "friend") - now we had to implement 2 methods for no reason.
That's what the Interface Segregation principle was warning us about!
Ok, so we know it's bad. We've had enough of these hacky 'solutions' - what are our options for a real fix?
Accepted Solutions
There are two ways that the Interface Segregation Principle is normally satisfied. Both involve dividing our large interface into multiple smaller ones.
Role Interfaces
The first option is to create a new interface for each role that can be filled by our interface.
Each of these new interfaces is called a Role Interface.
In our case, the StringList interface fills two roles:
- Searching - finding elements in the list
- Mutation - editing the contents of the list
We should extract these roles into their own interfaces.
The replaceElement function uses both roles, so we still need an interface with all 3 methods.
That means we now have 3 interfaces:
Interfaces
interface Searchable {
indexOf(elem: string): number | null;
}
interface Mutable {
add(elem: string, idx: number);
remove(idx: number): boolean;
}
interface StringList {
add(elem: string, idx: number);
remove(idx: number): boolean;
indexOf(elem: string): number | null;
}
And our methods can be edited to specify which role they use.
The contains method searches the list, and the setElement method mutates the list.
The replaceElement method does both.
Their method signatures now look like this:
Method Signatures
function contains(list: Searchable, elem: string): boolean;
function setElement(list: Mutable, idx: number, newElem: string): boolean;
function replaceElement(
list: StringList,
oldElem: string,
newElem: string
): boolean;
Using our immutable list from before, contains(list, "friend") works fine.
More importantly, replaceElement(list, "hi", "hello") correctly causes a compiler error.
If we implemented add and remove, we could call setElement and replaceElement.
This clearly satisfies the Interface Segregation Principle.
It wasn't easy though - defining the boundary of each role is complex and gets harder with bigger interfaces. It can be difficult to use Role Interfaces and they need adjusting when functionality is added. Also, it is hard to slowly refactor an existing codebase to use Role Interfaces, as most of the effort happens at first when breaking down the large interfaces.
There are other downsides too - any documentation on StringList needs to be copied to Searchable and Mutable.
These are likely to get out-of-sync, and we don't have a single source of truth, since each method is defined in multiple places.
Single-Method Interfaces
Taking Role Interfaces to an extreme reveals a second option. We could define each method in its own Single-Method Interface (SMI). We can then combine interfaces using intersection types.
We don't need the StringList interface anymore, so we can remove than and replace it with single-method interfaces:
Single-method Interfaces
interface I_add {
add(elem: string, idx: number);
}
interface I_remove {
remove(idx: number): boolean;
}
interface I_indexOf {
indexOf(elem: string): number | null;
}
Then we rewrite our methods so that any parameter with type StringList now specifies which methods it uses.
The new method signatures are:
SMI Signuatures
function contains(list: I_indexOf, elem: string): boolean;
function setElement(
list: I_add & I_remove,
idx: number,
newElem: string
): boolean;
function replaceElement(
list: I_indexOf & I_add & I_remove,
oldElem: string,
newElem: string
): boolean;
As before, this correctly allows contains but not replaceElement when our list has only implemented indexOf.
Implementing add and remove would satisfy I_add and I_remove, allowing us to call setElement and replaceElement.
It can be confusing at first, and you end up with a lot of interfaces.
It's also a pain to implement on a legacy project.
Most of the refactoring work happens up-front, deleting and recreating any interfaces.
On the plus side, we keep our single source of truth for each method, and we can move the documentation from StringList to the SMIs.
Both solutions are workable, and in many other languages there is no alternative. Thankfully, TypeScript provides a third option.
Introducing Pick
In TypeScript, Pick is a built-in utility type.
Given a complex type, we can select some of its functionality and ignore the rest:
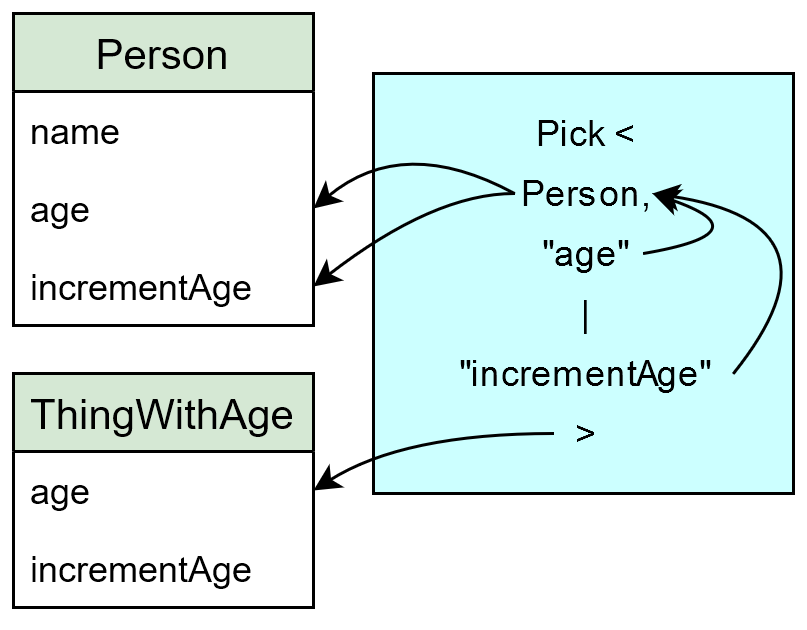
Pick Example
type Person = {
name: string;
age: number;
incrementAge: () => void;
};
type ThingWithAge = Pick<Person, "age" | "incrementAge">;
The ThingWithAge type selects the age and incrementAge properties from the Person type.
The resulting type is:
Equivalent to Pick
type ThingWithAge = {
age: number;
incrementAge: () => void;
};
The strings are concerning, but it's completely type-safe.
The compiler won't let you use Pick<Person, "nonExistentField">, as nonExistentField is not a property on Person.
This is thanks to String Literal types - a huge topic in and of itself.
Interface Segregation with Pick
We can use Pick to select parts of our large StringList interface.
Our interface is the same as it was in the first example:
Interface
interface StringList {
add(elem: string, idx: number);
remove(idx: number): boolean;
indexOf(elem: string): number | null;
}
We then edit our utility functions so that their list parameters use Pick to choose the relevant parts of StringList.
Utility Methods
function contains(list: Pick<StringList, "indexOf">, elem: string): boolean {
return list.indexOf(elem) !== null;
}
function setElement(
list: Pick<StringList, "add" | "remove">,
idx: number,
newElem: string
): boolean {
const removed = list.remove(idx);
if (!removed) return false;
list.add(newElem, idx);
}
function replaceElement(
list: Pick<StringList, "indexOf" | "add" | "remove">,
oldElem: string,
newElem: string
): boolean {
const idx = list.indexOf(oldElem);
if (idx === null) return false;
return setElement(list, idx, newElem);
}
Again, this solves our problem by allowing contains and not replaceElement.
We also don't need to write or modify any interfaces, allowing bad codebases to be refactored on a per-function basis.
Even better, our documentation works out of the box - it is automatically exposed by Pick.

You may think it strange that in replaceElement we used the type Pick<StringList, "indexOf" | "add" | "remove">.
Since StringList only has those 3 methods, it's equivalent to just using StringList as the type for list.
Listing the methods is best practice, even when you must list all of them.
That way, when more methods are added to StringList, we don't automatically require them in replaceElement.
Another point of confusion around replaceElement is that we require the add and remove methods on list even though we don't explicitly use them.
We need those methods because they are required by setElement.
This can be a pain, as it requires looking at the definition for every method used.
Also, if setElement added another method to the type for list, every function that used setElement would also have to be updated.
There is a solution to this problem, but it might get confusing. First, we need to define our own custom utility type:
A Solution
type Parameter<
T extends (...args: any) => any,
idx extends number
> = Parameters<T>[idx];
So, what does that do?
Our Parameter type depends on Parameters, a base TypeScript utility type.
To understand our type, we first need to understand Parameters.
It's hard to describe in words, but easy to demonstrate.
We have a function function myFunc(a: string, b: number): boolean.
Its type is (a: string, b: number) => boolean.
Parameters<typeof myFunc> returns [string, number] - a tuple of the parameter types for myFunc.
If you're still confused, click the link above for more examples.
Our utility type simply extracts one element of that tuple.
Parameter<typeof myFunc, 0> is the same as Parameters, which resolves to string.
We can use this utility type in the definition of replaceElement:
Using Utility
function replaceElement(
list: Pick<StringList, "indexOf"> & Parameter<typeof setElement, 0>,
oldElem: string,
newElem: string
): boolean;
Essentially, this says:
replaceElement accepts a parameter called list.
I'm going to call the indexOf method on it, and I'm going to pass it as the first argument to setElement.
Make sure it can also do whatever setElement needs.
Chaining
One difficulty with tightening our function parameters is the ability to do method chaining. For instance, in the first example, we could write a method:
Chaining
function chaining(list: StringList): StringList {
setElement(list, 0, "example");
return list;
}
And could use it as chaining(list).indexOf("friend").
It's not that simple when using segregated interfaces:
If we declare function chaining(list: Mutable): Mutable, then we can't call chaining(list).indexOf("friend").
chaining(list) outputs Mutable, even if the list parameter was actually a subtype of Mutable.
Since Mutable does not provide a indexOf method, we can't call it.
The same issue occurs with Single-Method Interfaces and Pick.
Instead, we have to use generics:
Chaining with Generics
// Role Interfaces
function chaining<T extends Mutable>(list: T): T;
// Single Method Interfaces
function chaining<T extends I_add & I_remove>(list: T): T;
// Pick
function chaining<T extends Pick<StringList, "add" | "remove">>(list: T): T;
Now the output of the chaining method is the same as the type of the list parameter.
If list implements indexOf, we can do chaining(list).indexOf("friend").
Conclusion
Interface Segregation is an important part of clean code and is essential for long-term maintainability of object-oriented code.
With TypeScript, it's simple to use Pick to divide up a large interface.
It's interoperable with old code, and once you understand how it works, there's no downside.
Do yourself a favour and start using Pick today.
